本文首发于2026年4月9日。在AlphaGo攻克围棋十年后的今天,桥牌——这项被称为“智力运动之王”的不完全信息博弈,正迎来AI技术的新一轮突破。本文将为技术学习者和开发者系统梳理桥牌AI助手的技术演进、核心算法与实践要点。
桥牌AI助手——即运用人工智能技术辅助桥牌叫牌、打牌决策或教学的系统——正从传统规则引擎向深度学习与LLM(Large Language Model,大语言模型)融合的新范式迈进。对于技术学习者和开发者而言,理解桥牌AI的设计思想、核心算法与实现路径,不仅有助于掌握不完全信息博弈的AI解决方案,更能为构建复杂决策系统提供宝贵的经验参照。本文将从传统实现方式的痛点切入,系统讲解基于规则引擎、深度学习、强化学习以及LLM的四种桥牌AI架构,并通过代码示例和面试要点,帮助读者建立从概念到落地的完整知识链路。

一、痛点切入:为什么需要桥牌AI助手?
传统桥牌学习与对弈系统的实现方式,大多采用硬编码规则引擎。以叫牌系统为例,其核心逻辑类似这样:
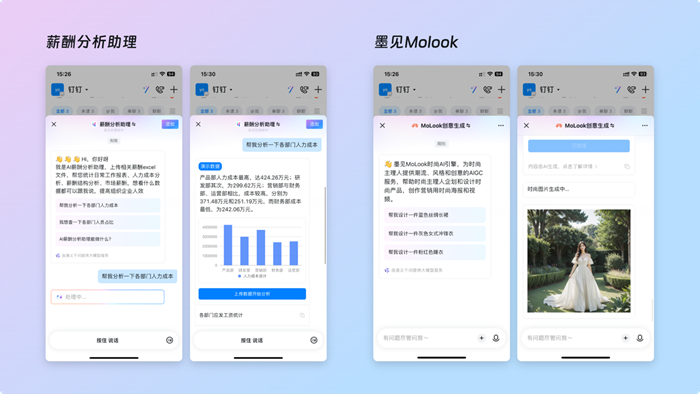
传统规则引擎示例 def get_bid(hand_points, suit_length, partner_bid, opponent_bid): if partner_bid == "PASS" and hand_points >= 13: return "1♣" 开叫 elif partner_bid == "1♠" and hand_points >= 6 and spade_length >= 3: return "2♠" 加叫 elif partner_bid == "1NT" and hand_points >= 8: return "2NT" 邀局 ... 成百上千条规则,覆盖各种边角情况 else: return "PASS"
这种方式的缺点十分明显:
扩展性差:桥牌叫牌体系繁多(自然制、精确制、蓝梅花等),规则组合呈指数级增长。据Luc Bellicaud(IntoBridge平台Lia机器人的开发者)的分析,机器人叫牌本质上是“一长串条件判断:若X则叫Y”,这让机器人具备了规则永不忘记的优势,但也注定了无法穷举所有可能场景-42。
缺乏灵活推理:当出现规则库未覆盖的“边缘情形”时,传统规则引擎会直接失效,无法像人类一样“临场发挥”-42。
难以整合学习数据:规则引擎无法从海量牌局数据中自我进化,性能天花板明显。
正是在这一背景下,融合深度学习的智能叫牌模型应运而生,标志着桥牌AI助手从规则驱动迈向了数据驱动的新阶段-。
二、核心概念讲解:不完全信息博弈
不完全信息博弈(Imperfect Information Game)是理解桥牌AI助手的基础概念。其标准定义为:参与者无法获知游戏中所有状态信息的博弈类型。
与围棋、象棋等完全信息博弈不同,桥牌玩家看不到对手的手牌,只能通过叫牌和出牌行为推断未知信息。桥牌的这一特性使其成为AI领域最具挑战性的难题之一——目前尚无桥牌程序能在正式比赛中击败人类职业牌手-26。
生活化类比:想象你在玩“谁是卧底”——你不知道谁是卧底,只能通过别人说的词来推测。桥牌AI助手的核心任务,正是在这种信息不完整的环境中做出最优决策。
三、关联概念讲解:叫牌阶段 vs 打牌阶段
桥牌博弈分为两大阶段,二者在AI实现上有着显著差异:
叫牌阶段:四人轮流进行“叫品”,最终确定定约(Contract,含将牌花色和需完成墩数)。这是一个多轮交互的协作与博弈过程——同伴之间需要传递手牌信息,同时干扰对手的判断。AI在这一阶段的核心挑战是:在信息不完备的条件下做出合理的叫牌决策,这比完全信息游戏难得多-24。
打牌阶段:首攻人打出第一张牌后,四人依次出牌,争夺13墩牌中的定约所需墩数。AI在这一阶段面临的核心问题是:如何进行高效与评估。
两者关系:叫牌阶段的决策质量直接决定了打牌阶段的起点和难度;打牌阶段的执行结果反过来验证叫牌决策的优劣。一个完整的桥牌AI助手需要同时处理好这两个阶段的博弈。
四、概念关系与区别总结
一句话记忆:叫牌阶段的AI是做“信息传递与策略博弈”,打牌阶段的AI是做“与概率评估”。
| 维度 | 叫牌阶段 | 打牌阶段 |
|---|---|---|
| 信息量 | 极不完备(仅知自己的手牌和叫品序列) | 逐步完备(已出牌张不断暴露) |
| 核心算法 | 规则引擎 + 深度学习模型 | 蒙特卡洛模拟 + 双明手求解 |
| 难点 | 信息隐含、体系复杂、需要协作推理 | 空间大、需实时决策 |
| 前沿技术 | LSTM+DRL、Diverse PPO、LLM推理 | α-β剪枝、神经网络估值 |
五、代码示例:现代桥牌AI助手的核心实现
5.1 基于深度神经网络的叫牌模型
以下是一个基于LSTM(Long Short-Term Memory,长短期记忆网络)的叫牌模型核心框架,来自学术研究的简化实现:
import torch import torch.nn as nn class BridgeBiddingLSTM(nn.Module): def __init__(self, input_dim=128, hidden_dim=256, output_dim=35): """ input_dim: 手牌特征编码维度(13张牌×4花色×点数编码) hidden_dim: LSTM隐藏层维度 output_dim: 35种可能的叫品(1♣到7NT) """ super().__init__() self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True) self.fc = nn.Linear(hidden_dim, output_dim) def forward(self, hand_embedding, bidding_history): bidding_history: 历史叫品序列(tensor格式) lstm_out, _ = self.lstm(bidding_history) final_state = lstm_out[:, -1, :] 取最后一个时间步 结合当前手牌特征 combined = torch.cat([final_state, hand_embedding], dim=1) 输出各叫品的概率分布 return torch.softmax(self.fc(combined), dim=1)
关键创新点:该模型通过LSTM捕捉叫品序列的时序依赖关系,结合手牌嵌入特征,输出下一步叫品的概率分布。实验表明,基于LSTM和深度强化学习的叫牌模型已在标准测试上优于传统冠军程序WBridge5-24。
5.2 基于强化学习的策略优化
Diverse PPO Ensembling(多样化PPO集成)是目前领先的桥牌叫牌优化方法,其核心思路是通过多样化约束避免模型陷入局部最优-24:
PPO策略更新核心伪代码 def ppo_update(policy_net, old_policy, trajectories, clip_epsilon=0.2): for _ in range(epochs): for states, actions, advantages in trajectories: 计算新旧策略的概率比 ratio = exp(policy_net(states).log_prob(actions) - old_policy.log_prob(actions)) 剪切目标函数 surrogate1 = ratio advantages surrogate2 = torch.clamp(ratio, 1-clip_epsilon, 1+clip_epsilon) advantages policy_loss = -torch.min(surrogate1, surrogate2).mean() 熵正则化:鼓励探索 entropy_bonus = policy_net(states).entropy().mean() loss = policy_loss - beta entropy_bonus loss.backward()
效果数据:该方法在深度强化学习阶段已超越WBridge5达0.73 IMP(国际比赛分),结合方法后优势进一步扩大至0.99 IMP-24。
5.3 基于LLM + RAG的AI助手工作流
Dify平台提供了一个低门槛构建桥牌AI助手的方案,通过将叫牌解释任务拆解为可编排的模块链条,使得非算法背景的教练也能构建具备“类教练思维”的AI助手-1。
核心工作流分为三个层级:
语义解析层:LLM将自然语言叫牌问题结构化
知识检索层:RAG(Retrieval-Augmented Generation,检索增强生成)从向量数据库检索相关叫牌规则
策略推导层:综合推理给出合理化建议
该方案的优势在于:无需手动维护海量规则,利用大语言模型的泛化能力和外部知识库的精准性,实现可扩展的叫牌教学与辅助系统。
六、底层原理与技术支撑
现代桥牌AI助手的底层技术栈可归纳为四大支柱:
1. 手牌表示学习:将一副13张牌的分布映射到向量空间是基础工作。研究人员已提出利用神经网络将牌手手牌嵌入向量空间的方案,为后续深度学习提供标准化输入-。
2. 双明手求解器:双明手求解器(Double Dummy Solver)是打牌阶段的核心工具,能够在假设所有手牌公开的情况下计算最优出牌路径,为AI决策提供理论下界-3。
3. 蒙特卡洛模拟:在不完全信息条件下,通过大量随机采样未知手牌的分布来逼近最优策略。改进算法如LeadGenius利用叫牌阶段信息引导采样策略,已超越Wbridge5和锦标赛级别的人类专家-4。
4. 深度强化学习框架:通过自对弈(Self-Play)让AI在虚拟对局中不断进化,外层学习框架利用AI自玩生成的数百万牌局数据扩充训练集,显著提升预测精度-。
七、高频面试题与参考答案
Q1:不完全信息博弈AI与完全信息博弈AI的主要差异是什么?
参考答案:完全信息博弈AI(如AlphaGo)可以基于完整的局面状态进行和评估;而不完全信息博弈AI需要处理信息集(Information Set)——即一组与当前观测一致的未知状态。桥牌AI需要从叫牌序列和已出牌张中推断未知信息,这需要引入信念状态(Belief State)的维护和更新机制,常通过蒙特卡洛采样或神经网络推理来实现。
Q2:桥牌AI中规则引擎与深度学习模型各自的优劣势是什么?
参考答案:
规则引擎:优势是可解释性强、行为可预测、不存在“幻觉”;劣势是无法覆盖所有边缘场景,维护成本随规则数量爆炸式增长。
深度学习模型:优势是能从数据中自主学习复杂模式,泛化能力强;劣势是行为可能不可预测、训练数据需求量大、可解释性差。
当前趋势:混合架构——用规则引擎处理核心体系,用深度学习模型处理不确定性高的边缘决策。例如GIBBO的升级就是保留规则系统,但将叫牌结果评估从双明手分析替换为神经网络估值-41。
Q3:为什么桥牌比围棋更难被AI攻克?
参考答案:核心在于信息不完全性和协作博弈的双重挑战。围棋是完美信息博弈,所有信息对双方透明;而桥牌中,牌手只能看到自己的手牌,需在信息不完备条件下做出决策。更关键的是,桥牌需要与同伴协作——AI不仅要理解对手的策略,还要推断同伴的意图并传递自己的信息,这是单智能体优化无法解决的多智能体协作博弈问题。目前尚无桥牌程序能在正式比赛中击败人类职业牌手。
Q4:LLM能否直接用于桥牌叫牌决策?
参考答案:LLM虽然具有强大的语义理解能力,但直接用于叫牌决策面临三大问题:一是缺乏对桥牌规则的确切约束,可能产生不合规的叫品;二是无法保证决策的一致性;三是缺乏对不完全信息博弈的专门优化。当前更可行的路径是LLM辅助教学与解释 + 专用博弈模型做决策的混合架构。正如Luc Bellicaud所指出,LLM仍无法替代精心编写的桥牌逻辑-5。
Q5:如何评估一个桥牌AI助手的性能?
参考答案:主要评估指标包括:
IMP/MP得分:与国际比赛分相关的对抗性指标
叫牌准确率:与专家标注的最佳叫品对比
双明手差距:AI打牌结果与双明手最优解的差距
人类专家对战胜率:最终的性能验证标准
八、结尾总结
本文系统梳理了桥牌AI助手的技术全景:
核心知识点回顾:
桥牌属于不完全信息博弈,与完全信息博弈在AI实现上存在根本差异
传统规则引擎的局限性催生了深度学习+强化学习的融合架构
叫牌阶段侧重信息传递与策略博弈,打牌阶段侧重与概率评估
当前前沿方向包括Diverse PPO Ensembling(提升策略优化鲁棒性)、LeadGenius首攻算法(利用叫牌信息引导采样)、以及LLM+RAG辅助教学(降低技术门槛)
易错点提醒:
不要将桥牌与围棋的AI解法混为一谈——信息完备性差异决定了技术路径的根本不同
深度学习模型虽强大,但可解释性差是其应用于正式比赛的障碍
规则引擎在核心逻辑上仍有不可替代的价值,尤其是保证行为合规性
进阶预告:下一篇将深入剖析深度强化学习在桥牌叫牌中的完整实现流程,包括手牌表示网络设计、奖励函数设定、自对弈环境搭建等工程实践,敬请期待。
参考资料:Dify平台桥牌应用实践(2025.12);LeadGenius首攻算法论文(Information Sciences, Volume 728, 2026);分步协同桥牌智能博弈策略研究(重庆理工大学学报,2025);Lia机器人开发者Luc Bellicaud的技术分享(2025-2026);GIBBO神经网络升级公告(Bridge Base Online,2025.12);Diverse PPO Ensembling论文(IEEE Access, 2025)