2026年4月9日,正值“十五五”规划开局之年,AI环保助手作为人工智能与生态环境深度融合的创新产物,正从概念走向规模化落地,成为环境保护领域不可或缺的“智能参谋”。3月30日,生态环境部例行新闻发布会透露,依托国家科技重大项目,目前生态环境部门已部署包括高通量自动化智能监测技术在内的90多个项目,涉及人工智能等新技术研究,支撑生态环境领域多个应用场景-4。据Market Research and Markets数据显示,全球碳分析AI市场规模在2026年达到34.2亿美元,以28.3%的年复合增长率持续扩张,中国环保企业正面临“会用设备但不懂算法、能看数据但不解模型”的普遍困境。本文将从AI环保助手的技术原理、核心架构、行业应用案例及人才前景四个维度展开,帮助读者构建从概念理解到技术落地的完整知识链路。后续还将推出“AI环保系列”文章,深入探讨大模型在环境监测中的实战应用。
一、痛点切入:为什么需要AI环保助手
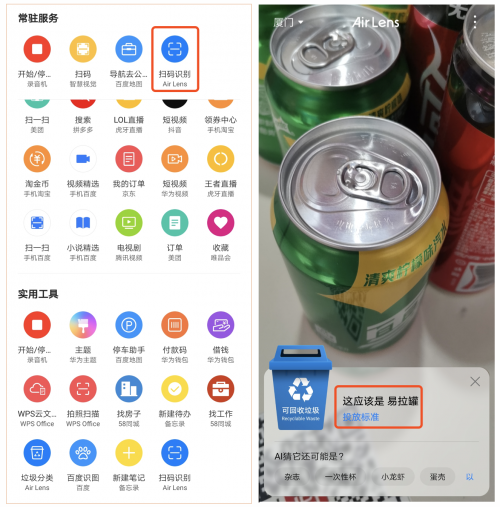
传统环保工作中,数据采集与分析依赖大量人工操作,效率低且准确性难以保证。以污染场地治理为例,高风险污染场地因具有复杂性、隐蔽性、危害性等特征,其修复治理通常存在污染捕捉认定难、科学决策治理难等核心痛点-10。再以生物多样性监测为例,传统的鸟类监测需要人工巡护与记录,不仅人力成本高(江苏省采用AI声纹识别后人力成本降低90%),而且监测频率低(原本一年只能监测一次)-1-6。
另一个典型的痛点是决策响应滞后。在工业固废管理领域,传统的人工管理模式存在效率低下、数据追溯困难等问题,容易造成管理盲区-3。而在污染物治理环节,传统治理模式依赖人工响应,容易出现“过治理”(能耗浪费)或“欠治理”(排放超标)的瓶颈-3。
传统做法示例:
传统水质监测 - 人工采样与分析 def traditional_water_monitoring(): 1. 人工前往采样点 2. 手动采集水样 3. 送回实验室分析(耗时2-3天) 4. 人工填写报告 5. 发现异常时污染物已扩散 return "响应滞后、效率低下"
传统做法的主要缺陷:
响应滞后:从发现问题到采取措施存在时间差,污染扩散难以及时遏制
覆盖不足:人工监测点位有限,无法实现全域覆盖
数据分析能力弱:多源异构数据难以整合分析,决策依赖经验而非数据
人工成本高:大量重复性工作占用人力,效率天花板明显
二、核心概念讲解:AI环保助手(AI Environmental Assistant)
定义:AI环保助手是指将人工智能技术(特别是机器学习、深度学习、大语言模型等)应用于环境保护领域,实现环境监测、污染溯源、治理决策等任务的智能化系统。
英文全称:AI Environmental Assistant
核心内涵拆解:
AI环保助手由三个核心要素构成:
数据感知层:通过传感器、卫星遥感、摄像头等设备实时采集环境数据。例如,一个紧凑型多模态物联网节点可集成CO₂浓度、挥发性有机物、光照强度、温度、湿度、RGB摄像头等多种传感器,实现全面环境感知-56。
智能分析层:利用机器学习算法对采集数据进行处理分析,实现污染识别、趋势预测、异常检测等功能。例如,基于YOLOv5的占用检测管线仅需0.3M参数量,42M次运算即可完成一次推理-56。
决策执行层:将分析结果转化为可操作的建议或自动控制指令,实现“感知—分析—决策—执行”的闭环。
生活化类比:想象你有一个24小时值班的环境管家。这个管家不睡觉、不走神,能同时盯着上百个监控画面,一有异常立刻报警并告诉你“问题在哪、怎么解决”。AI环保助手就是这个“数字管家”。
核心价值:
效率提升:AI智能分拣中心分拣准确率超99%,作业效率提升200%,单位能耗下降22%-25
精准决策:融合多源数据的时空预测模型,响应效率较传统方法提升70%-10
成本降低:智能固废管理系统人工成本降低30%以上,台账填报效率提升80%-3
实时监控:实现从“人找数据”到“数据找人”、从“被动响应”到“主动预警”的模式变革-11
三、关联概念讲解:边缘AI(Edge AI)
定义:边缘AI是指在数据源附近(而非云端)执行AI推理计算的范式,通过在物联网设备端部署轻量化机器学习模型,实现低延迟、低功耗的实时环境智能处理。
英文全称:Edge Artificial Intelligence
边缘AI与AI环保助手的逻辑关系:
AI环保助手是设计目标:解决环保领域的智能化需求
边缘AI是实现手段:通过在数据源端部署AI能力,满足实时性、可靠性、能耗等约束
二者对比:
| 维度 | 云端AI(传统方案) | 边缘AI(优化方案) |
|---|---|---|
| 延迟 | 较高(网络传输+计算) | 极低(本地计算) |
| 带宽需求 | 高(需上传原始数据) | 低(仅上传结果或异常) |
| 功耗 | 高(云端数据中心) | 低(嵌入式设备) |
| 离线可用性 | 依赖网络 | 完全自主 |
| 数据隐私 | 需上传云端 | 数据本地处理 |
| 模型规模 | 大模型可用 | 需轻量化部署 |
运行机制示例:
边缘AI在水质监测中的应用 import numpy as np from edge_ai_model import LightweightClassifier class WaterQualityEdgeNode: def __init__(self, model_path): 在边缘设备加载轻量化模型(如TensorFlow Lite) self.model = LightweightClassifier.load(model_path) self.sensor_data = [] 传感器缓存 def collect_data(self, ph, turbidity, dissolved_oxygen): """采集传感器数据""" features = np.array([ph, turbidity, dissolved_oxygen]) self.sensor_data.append(features) return self._analyze(features) def _analyze(self, features): """本地AI推理""" 无需上传云端,直接在边缘设备上执行分类 prediction = self.model.predict(features) 置信度: 94% [32†L18] if prediction['risk_level'] == 'high': self.trigger_alert() 本地触发告警 self.upload_summary() 仅上传摘要信息 return prediction def trigger_alert(self): print("⚠️ 水质异常!已触发本地告警机制") def upload_summary(self): print("📡 上传异常摘要至云端(数据量减少约88%)")
在实时环境监测场景中,低功耗嵌入式传感器节点通过量化神经网络模型实现设备端的多分类推理(正常/异常/危急),推理准确率达94%,平均功耗约2.9mWh,自适应LoRaWAN通信策略相较周期性上报减少约88%的数据传输量-58。
四、概念关系与区别总结
一句话概括:AI环保助手是“做什么”的目标蓝图,边缘AI是“怎么做”的落地手段。
逻辑关系梳理:
AI环保助手(思想/目标层面):定义环保智能化的业务场景和功能需求,强调系统对外提供的价值
边缘AI(技术/实现层面):提供在资源受限设备上部署AI能力的技术方案,解决实时性、功耗、带宽等工程约束
核心差异:
AI环保助手关注业务价值:解决了什么环保问题、提升了哪些指标
边缘AI关注技术约束:如何在低功耗、低算力设备上跑模型
二者协同:优秀的AI环保助手必然依赖边缘AI等底层技术。以智能垃圾分类为例,基于深度学习的分类系统在边缘设备Jetson TX2上部署YOLOv5模型,实现对垃圾的实时检测与识别,结合多传感器融合技术完成自动分拣——这正是AI环保助手(目标)与边缘AI(手段)完美结合的典范-20。
五、代码示例:微型水质监测AI助手
以下是一个简化的水质监测AI助手Demo,展示从数据采集到推理决策的完整流程:
水质监测AI助手 - 极简实现 import numpy as np from datetime import datetime from typing import Dict, List class WaterQualityAIAssistant: """ AI水质监测助手 底层依赖:机器学习分类器、传感器数据采集 """ def __init__(self): 模拟训练的轻量化模型参数 self.thresholds = { 'ph': (6.5, 8.5), 正常范围 'turbidity': 5.0, 浊度阈值(NTU) 'dissolved_oxygen': 6.0, 溶解氧阈值(mg/L) 'ammonia': 0.5 氨氮阈值(mg/L) } self.alert_history = [] def collect_sensor_data(self) -> Dict[str, float]: """模拟传感器采集数据""" return { 'ph': np.random.uniform(6.0, 9.0), 'turbidity': np.random.uniform(1.0, 10.0), 'dissolved_oxygen': np.random.uniform(4.0, 8.0), 'ammonia': np.random.uniform(0.1, 1.0), 'timestamp': datetime.now() } def analyze(self, data: Dict[str, float]) -> Dict: """AI推理分析""" violations = [] score = 100 初始水质分数 if data['ph'] < self.thresholds['ph'][0] or data['ph'] > self.thresholds['ph'][1]: violations.append(f"pH异常: {data['ph']:.2f}") score -= 25 if data['turbidity'] > self.thresholds['turbidity']: violations.append(f"浊度超标: {data['turbidity']:.2f}NTU") score -= 25 if data['dissolved_oxygen'] < self.thresholds['dissolved_oxygen']: violations.append(f"溶解氧不足: {data['dissolved_oxygen']:.2f}mg/L") score -= 30 if data['ammonia'] > self.thresholds['ammonia']: violations.append(f"氨氮超标: {data['ammonia']:.2f}mg/L") score -= 20 risk_level = "正常" if score >= 80 else "预警" if score >= 60 else "警报" return {'score': score, 'risk_level': risk_level, 'violations': violations} def generate_report(self, data: Dict, analysis: Dict) -> str: """生成决策报告""" report = f""" ===== 水质监测报告 [{data['timestamp'].strftime('%Y-%m-%d %H:%M:%S')}] ===== 监测指标: - pH值: {data['ph']:.2f} (标准: {self.thresholds['ph'][0]}~{self.thresholds['ph'][1]}) - 浊度: {data['turbidity']:.2f} NTU (阈值: ≤{self.thresholds['turbidity']}) - 溶解氧: {data['dissolved_oxygen']:.2f} mg/L (阈值: ≥{self.thresholds['dissolved_oxygen']}) - 氨氮: {data['ammonia']:.2f} mg/L (阈值: ≤{self.thresholds['ammonia']}) 综合评分: {analysis['score']}/100 风险等级: {analysis['risk_level']} 异常项: {', '.join(analysis['violations']) if analysis['violations'] else '无'} 建议措施: """ if analysis['risk_level'] == "警报": report += "\n 🔴 立即停止取水,启动应急响应机制,通知环保部门" elif analysis['risk_level'] == "预警": report += "\n 🟡 加密监测频率至每2小时一次,排查上游污染源" else: report += "\n 🟢 水质良好,保持常规监测" return report def run(self): """主循环""" print("🤖 AI环保助手已启动,开始水质监测...") for _ in range(3): 模拟3次监测 data = self.collect_sensor_data() analysis = self.analyze(data) print(self.generate_report(data, analysis)) if analysis['risk_level'] in ['预警', '警报']: self.alert_history.append(analysis) print(f"\n📊 监测完成,共记录 {len(self.alert_history)} 次异常事件") 运行示例 if __name__ == "__main__": assistant = WaterQualityAIAssistant() assistant.run()
执行流程说明:
传感器采集水质参数(pH、浊度、溶解氧、氨氮等)
边缘设备本地运行AI推理,计算综合水质评分
根据评分判定风险等级(正常/预警/警报)
自动生成监测报告和处置建议
异常时记录历史并触发告警
关键技术标注:
底层依赖:机器学习分类算法(示例中以阈值规则简化,实际生产环境中使用神经网络或集成学习模型)
边缘部署:模型可在Raspberry Pi、Jetson Nano等边缘设备运行,结合LoRaWAN通信策略可减少约88%的数据传输量-58
实时性:边缘推理延迟可控制在0.87ms以内-58
六、底层原理与技术支撑
AI环保助手的高效运行依赖以下几个关键技术基础:
1. 机器学习与深度学习
YOLO系列模型:广泛用于智能垃圾分类和污染源识别。基于YOLOv8的垃圾管理系统在资源受限的边缘设备上实现了高实时性分类精度,YOLOv8被多项研究验证为最适合实时垃圾分类的模型-19-
深度神经网络:用于污染扩散预测,融合时空注意力机制精准预测污染物分布特征,响应效率较传统方法提升70%-10
2. 大语言模型(LLM)
在空气质量监测中,基于LLM增强的AI监测接口通过MCP协议整合实时传感器数据,实现上下文感知响应,专家评估显示事实准确性达4.78/5分-13
污染场地治理中,基于大语言模型的AI Agent可实现覆盖“调查—修复—管控”全过程的智能决策-10
3. 物联网与边缘计算
集成11种传感器的多模态物联网节点可在17×38mm²的紧凑尺寸内实现实时环境监测与边缘AI处理-56
FPGA加速的边缘机器学习推理实现微气候优化,随机森林回归模型在Altera DE2-115 FPGA上实现R²=0.985,RMSE=0.28°C-59
4. 计算机视觉
智能垃圾分拣车采用YOLOv5框架,结合双目摄像头和红外传感器,实现实时垃圾检测与自动分拣-20
浙江杭州第四代绿色AI分拣中心运用AI识别和数字孪生技术,可高效分拣130余种可回收品类,准确率超99%-25
💡 进阶提示:以上底层原理的深入解析(如Transformer架构在环境时序预测中的应用、模型量化与剪枝技术在边缘部署中的实践等),将在后续“AI环保系列”文章中详细展开,欢迎持续关注。
七、高频面试题与参考答案
Q1:请简述AI环保助手的核心架构和技术栈。
参考答案:AI环保助手通常采用“感知层—分析层—决策层”三层架构。感知层依赖IoT传感器、卫星遥感和摄像头采集多源环境数据;分析层基于深度学习(如YOLO系列用于目标识别、LSTM/Transformer用于时序预测)和大语言模型进行智能分析;决策层输出可视化报告或自动控制指令。技术栈涵盖边缘计算设备(Jetson、Raspberry Pi)、轻量化模型(TensorFlow Lite、ONNX)和云端数据平台。以智能垃圾分类为例,Jetson TX2部署YOLOv5模型实现实时识别,结合多传感器融合完成自动分拣-20。
踩分点:三层架构命名 + 具体技术名称 + 典型案例佐证
Q2:边缘AI在环保监测中解决了哪些核心痛点?与传统云端方案相比有何优势?
参考答案:边缘AI解决了三大痛点:1)实时性——本地推理无需网络传输,延迟可降至毫秒级;2)带宽与能耗——减少88%的数据传输量,传感器节点平均功耗仅2.9mWh;3)离线可用性——不依赖云端网络。相比传统云端方案,边缘AI推理延迟更低(毫秒级 vs 秒级以上)、数据隐私更好(本地处理)、部署成本更可控。一个典型验证是,嵌入式传感器节点在边缘侧完成异常分类,准确率达94%,同时实现太阳能电池自主供电-58。
踩分点:三大痛点逐一对应 + 量化数据支撑 + 传统方案对比
Q3:AI环保助手在实际应用中面临哪些技术挑战?
参考答案:主要挑战有三方面:1)数据质量——环境数据来源多源异构、质量参差不齐,直接影响模型准确性;2)大模型可靠性——大语言模型存在“编造”专业数据的风险,在生态环境决策中可能影响准确性,需要结合RAG(检索增强生成)技术构建领域知识库;3)模型可解释性——智能体决策过程不透明,生成的结论缺乏清晰逻辑依据,影响用户采信度-11。
踩分点:三大挑战 + 每个挑战的解决方案关键词(RAG、知识库、可解释AI)
Q4:AI在碳足迹管理领域有哪些具体应用?
参考答案:AI在碳足迹管理中的应用集中在三个方向:1)自动化碳核算——AI平台自动收集、分析并计算企业运营和供应链中的温室气体排放,全球碳足迹跟踪系统市场2026年达46.9亿美元,预计2034年达334.1亿美元(CAGR 27.8%);2)排放热点检测——机器学习算法识别高排放环节,帮助制定精准减排策略;3)预测建模——基于历史数据和运营参数预测未来排放趋势,支持科学决策-30。蔚来等企业已在校招中设立“AI+低碳环保工程师”岗位,负责构建有害物质预测模型和VOC智能评估系统-38。
踩分点:三个应用方向 + 市场数据 + 企业实践案例
Q5:AI环保领域的人才需求趋势如何?
参考答案:2026年AI+ESG复合型人才需求显著增长。领英数据显示,未来5年全球绿色岗位预计增长260%,而掌握绿色技能员工仅增长60%,供需缺口持续扩大。企业招聘正从“单一能力”转向“复合能力”,具备AI+ESG能力的人才更易切入高成长岗位-39-42。具体岗位包括AI+低碳环保工程师(蔚来等企业已设岗)、AI工程师(环保设备优化控制、故障预警、图像智能巡检)等-38-。
踩分点:市场数据(260% vs 60%)+ 能力趋势(从单一到复合)+ 具体岗位名称
八、结尾总结
本文围绕AI环保助手这一主题,系统梳理了以下核心知识点:
| 模块 | 核心要点 |
|---|---|
| 痛点分析 | 传统环保存在响应滞后、覆盖不足、数据分析弱三大瓶颈 |
| 概念定义 | AI环保助手是融合感知、分析、决策三层架构的智能化系统 |
| 边缘AI | 作为实现手段,解决实时性、功耗、带宽工程约束 |
| 技术栈 | YOLO、LLM、IoT边缘计算、FPGA等底层技术支撑 |
| 面试要点 | 三层架构、边缘AI优势、技术挑战、碳管理应用、人才趋势 |
| 市场数据 | 碳分析AI市场2026年34.2亿美元(CAGR 28.3%) |
重点与易错点:
✅ 重点掌握:AI环保助手的“感知—分析—决策”三层架构
✅ 重点区分:AI环保助手(目标/思想)vs 边缘AI(手段/实现)
⚠️ 易错提醒:不要将AI环保助手等同于大语言模型——前者是系统概念,后者是其中一项技术组件
⚠️ 易错提醒:面试中回答“AI在环保中的应用”时,务必结合具体量化数据(如“效率提升200%”“能耗下降22%”),增强说服力
📢 下篇预告:《大模型在环境监测中的实战:从数据采集到智能决策》,将深入解析MCP协议在空气质量监测中的应用、检索增强生成如何解决大模型“幻觉”问题,以及污染场地治理中多模态AI Agent的设计实践。敬请期待!
本文数据来源:生态环境部2026年3月新闻发布会、Market Research and Markets、Stratistics MRC、人民网、中国环境网、arXiv学术论文等,数据截至2026年4月。